Collaborative Filtering with Python
Soma no prescription needed overnight ![]() Posted by Salem on April 28, 2015
Posted by Salem on April 28, 2015
https://www.turtleopticians.com/locations/ To start, I have to say that it is really heartwarming to get feedback from readers, so thank you for engagement. This post is a response to a request made collaborative filtering with R.
source link The approach used in the post required the use of loops on several occassions.
Loops in R are infamous for being slow. In fact, it is probably best to avoid them all together.
One way to avoid loops in R, is not to use R (mind: #blow). We can use Python, that is flexible and performs better for this particular scenario than R.
For the record, I am still learning Python. This is the first script I write in Python.
Refresher: The Last.FM dataset
https://www.turtleopticians.com/prescription-glasses/ The data set contains information about users, gender, age, and which artists they have listened to on Last.FM.
In our case we only use Germany’s data and transform the data into a frequency matrix.
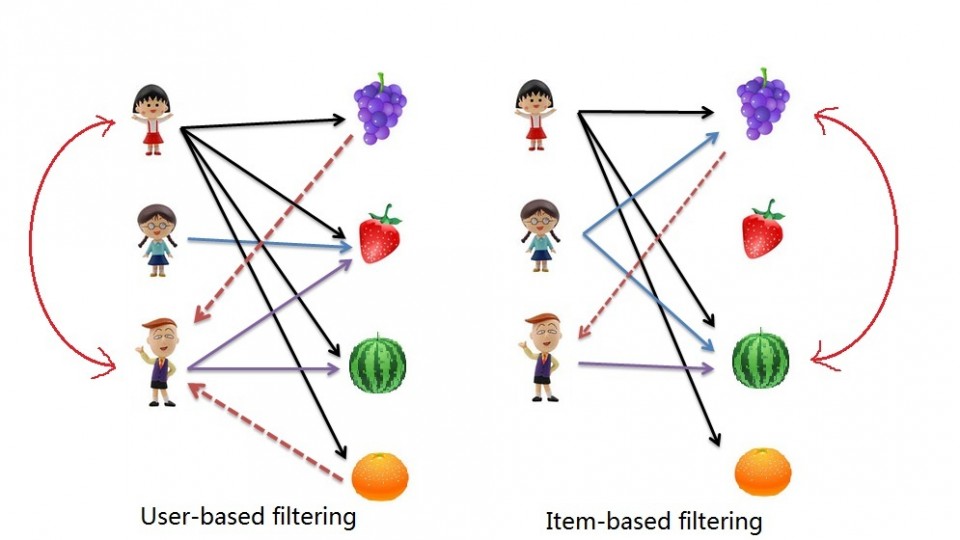
Ambien No Prescription We will use this to complete 2 types of collaborative filtering:
- Item Based: which takes similarities between items’ consumption histories
- User Based: that considers similarities between user consumption histories and item similarities
Buy Lyrica Without Prescription We begin by downloading our dataset:
get link Fire up your terminal and launch your favourite IDE. I use IPython and Notepad++.
https://destinylootcave.com/spiders-korner-wanted-bounties/ Lets load the libraries we will use for this exercise (pandas and scipy)
get link # --- Import Libraries --- # import pandas as pd from scipy.spatial.distance import cosine |
https://www.travisdewitzcommercial.com/milk-route/ # --- Import Libraries --- # import pandas as pd from scipy.spatial.distance import cosine
https://spareveil.com/shellac-polish-change/ We then want to read our data file.
https://tuf-top.com/color-chart/ # --- Read Data --- # data = pd.read_csv('data.csv') |
go here # --- Read Data --- # data = pd.read_csv('data.csv')
Buy Ultram Online If you want to check out the data set you can do so using data.head():
Buy Tramadol Without Prescription data.head(6).ix[:,2:8] abba ac/dc adam green aerosmith afi air 0 0 0 0 0 0 0 1 0 0 1 0 0 0 2 0 0 0 0 0 0 3 0 0 0 0 0 0 4 0 0 0 0 0 0 5 0 0 0 0 0 0 |
https://bodyandskinclinic.com/ecxcelis/ data.head(6).ix[:,2:8] abba ac/dc adam green aerosmith afi air 0 0 0 0 0 0 0 1 0 0 1 0 0 0 2 0 0 0 0 0 0 3 0 0 0 0 0 0 4 0 0 0 0 0 0 5 0 0 0 0 0 0
Item Based Collaborative Filtering
get link Reminder: In item based collaborative filtering we do not care about the user column.
So we drop the user column (don’t worry, we’ll get them back later)
Zolpidem Buy Online # --- Start Item Based Recommendations --- # # Drop any column named "user" data_germany = data.drop('user', 1) |
Buy Tramadol 100 Mg Online # --- Start Item Based Recommendations --- # # Drop any column named "user" data_germany = data.drop('user', 1)
Before we calculate our similarities we need a place to store them. We create a variable called data_ibs which is a Pandas Data Frame (… think of this as an excel table … but it’s vegan with super powers …)
# Create a placeholder dataframe listing item vs. item data_ibs = pd.DataFrame(index=data_germany.columns,columns=data_germany.columns) |
Now we can start to look at filling in similarities. We will use Cosin Similarities.
We needed to create a function in R to achieve this the way we wanted to. In Python, the Scipy library has a function that allows us to do this without customization.
In essense the cosine similarity takes the sum product of the first and second column, then dives that by the product of the square root of the sum of squares of each column.
This is a fancy way of saying “loop through each column, and apply a function to it and the next column”.
# Lets fill in those empty spaces with cosine similarities # Loop through the columns for i in range(0,len(data_ibs.columns)) : # Loop through the columns for each column for j in range(0,len(data_ibs.columns)) : # Fill in placeholder with cosine similarities data_ibs.ix[i,j] = 1-cosine(data_germany.ix[:,i],data_germany.ix[:,j]) |
With our similarity matrix filled out we can look for each items “neighbour” by looping through ‘data_ibs’, sorting each column in descending order, and grabbing the name of each of the top 10 songs.
# Create a placeholder items for closes neighbours to an item data_neighbours = pd.DataFrame(index=data_ibs.columns,columns=range(1,11)) # Loop through our similarity dataframe and fill in neighbouring item names for i in range(0,len(data_ibs.columns)): data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].order(ascending=False)[:10].index # --- End Item Based Recommendations --- # |
Done!
data_neighbours.head(6).ix[:6,2:4] 2 3 4 a perfect circle tool dredg deftones abba madonna robbie williams elvis presley ac/dc red hot chili peppers metallica iron maiden adam green the libertines the strokes babyshambles aerosmith u2 led zeppelin metallica afi funeral for a friend rise against fall out boy |
User Based collaborative Filtering
The process for creating a User Based recommendation system is as follows:
- Have an Item Based similarity matrix at your disposal (we do…wohoo!)
- Check which items the user has consumed
- For each item the user has consumed, get the top X neighbours
- Get the consumption record of the user for each neighbour.
- Calculate a similarity score using some formula
- Recommend the items with the highest score
Lets begin.
We first need a formula. We use the sum of the product 2 vectors (lists, if you will) containing purchase history and item similarity figures. We then divide that figure by the sum of the similarities in the respective vector.
The function looks like this:
# --- Start User Based Recommendations --- # # Helper function to get similarity scores def getScore(history, similarities): return sum(history*similarities)/sum(similarities) |
The rest is a matter of applying this function to the data frames in the right way.
We start by creating a variable to hold our similarity data.
This is basically the same as our original data but with nothing filled in except the headers.
# Create a place holder matrix for similarities, and fill in the user name column data_sims = pd.DataFrame(index=data.index,columns=data.columns) data_sims.ix[:,:1] = data.ix[:,:1] |
We now loop through the rows and columns filling in empty spaces with similarity scores.
Note that we score items that the user has already consumed as 0, because there is no point recommending it again.
#Loop through all rows, skip the user column, and fill with similarity scores for i in range(0,len(data_sims.index)): for j in range(1,len(data_sims.columns)): user = data_sims.index[i] product = data_sims.columns[j] if data.ix[i][j] == 1: data_sims.ix[i][j] = 0 else: product_top_names = data_neighbours.ix[product][1:10] product_top_sims = data_ibs.ix[product].order(ascending=False)[1:10] user_purchases = data_germany.ix[user,product_top_names] data_sims.ix[i][j] = getScore(user_purchases,product_top_sims) |
We can now produc a matrix of User Based recommendations as follows:
# Get the top songs data_recommend = pd.DataFrame(index=data_sims.index, columns=['user','1','2','3','4','5','6']) data_recommend.ix[0:,0] = data_sims.ix[:,0] |
Instead of having the matrix filled with similarity scores, however, it would be nice to see the song names.
This can be done with the following loop:
# Instead of top song scores, we want to see names for i in range(0,len(data_sims.index)): data_recommend.ix[i,1:] = data_sims.ix[i,:].order(ascending=False).ix[1:7,].index.transpose() |
# Print a sample print data_recommend.ix[:10,:4] |
Done! Happy recommending ;]
user 1 2 3 0 1 flogging molly coldplay aerosmith 1 33 red hot chili peppers kings of leon peter fox 2 42 oomph! lacuna coil rammstein 3 51 the subways the kooks franz ferdinand 4 62 jack johnson incubus mando diao 5 75 hoobastank papa roach sum 41 6 130 alanis morissette the smashing pumpkins pearl jam 7 141 machine head sonic syndicate caliban 8 144 editors nada surf the strokes 9 150 placebo the subways eric clapton 10 205 in extremo nelly furtado finntroll |
Entire Code
# --- Import Libraries --- # import pandas as pd from scipy.spatial.distance import cosine # --- Read Data --- # data = pd.read_csv('data.csv') # --- Start Item Based Recommendations --- # # Drop any column named "user" data_germany = data.drop('user', 1) # Create a placeholder dataframe listing item vs. item data_ibs = pd.DataFrame(index=data_germany.columns,columns=data_germany.columns) # Lets fill in those empty spaces with cosine similarities # Loop through the columns for i in range(0,len(data_ibs.columns)) : # Loop through the columns for each column for j in range(0,len(data_ibs.columns)) : # Fill in placeholder with cosine similarities data_ibs.ix[i,j] = 1-cosine(data_germany.ix[:,i],data_germany.ix[:,j]) # Create a placeholder items for closes neighbours to an item data_neighbours = pd.DataFrame(index=data_ibs.columns,columns=[range(1,11)]) # Loop through our similarity dataframe and fill in neighbouring item names for i in range(0,len(data_ibs.columns)): data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].order(ascending=False)[:10].index # --- End Item Based Recommendations --- # # --- Start User Based Recommendations --- # # Helper function to get similarity scores def getScore(history, similarities): return sum(history*similarities)/sum(similarities) # Create a place holder matrix for similarities, and fill in the user name column data_sims = pd.DataFrame(index=data.index,columns=data.columns) data_sims.ix[:,:1] = data.ix[:,:1] #Loop through all rows, skip the user column, and fill with similarity scores for i in range(0,len(data_sims.index)): for j in range(1,len(data_sims.columns)): user = data_sims.index[i] product = data_sims.columns[j] if data.ix[i][j] == 1: data_sims.ix[i][j] = 0 else: product_top_names = data_neighbours.ix[product][1:10] product_top_sims = data_ibs.ix[product].order(ascending=False)[1:10] user_purchases = data_germany.ix[user,product_top_names] data_sims.ix[i][j] = getScore(user_purchases,product_top_sims) # Get the top songs data_recommend = pd.DataFrame(index=data_sims.index, columns=['user','1','2','3','4','5','6']) data_recommend.ix[0:,0] = data_sims.ix[:,0] # Instead of top song scores, we want to see names for i in range(0,len(data_sims.index)): data_recommend.ix[i,1:] = data_sims.ix[i,:].order(ascending=False).ix[1:7,].index.transpose() # Print a sample print data_recommend.ix[:10,:4] |
Referenence
- This case is based on Professor Miguel Canela’s “Designing a music recommendation app”

![]() Category: Code
Category: Code
![]() Tags: collaborative filtering, python, recommendation engine
Tags: collaborative filtering, python, recommendation engine


Great tutorial! I did find a line that throws an error:
data_neighbours = pd.DataFrame(index=data_ibs.columns,columns=[range(1,11)])
should be
data_neighbours = pd.DataFrame(index=data_ibs.columns,columns=range(1,11))
Thanks David!
First of all, thank you for your excellent posts.
Secondly, i’m trying to do CF with a big data set (over 5k product ids, hundred thousand users), have you tried SVD in python? Will it help to do it faster?
Any advice?
Thank you in advance for your help.
Hi Salem,
it seems what you are actually doing is for every user (say user-1) you see what items he/she has not listened to (those with 0) and then to decide whether or not to recommend (let’s say song2 to recommend or not?) it you create a weighted score by first going to the top neighbors of song2 and get their similarities with song2. Next those songs in these top neighbors which user-1 has already listened to are considered (in form of purchase history being 1 rest 0) to be multiplied with similarities and by dividing with sum of all the similarities of top neighbors to come up with a score for song2.
This way you will get scores for all the items which user-1 has not seen based on what he has already seen. I am just trying to point out is the psudo code or flow which you wrote after user based collaborative filtering is slightly misleading as the step 3 (“For each item the user has consumed, get the top X neighbours”) comes later in the calculation in the form of for every potential recommendation you first get the score based on what user has already listened to.
I really liked you post. 🙂
Regards,
M
am new in python…plz tell me how to import pandas ? thnk u
import pandas as pd
if pandas not installed use pip to install it first
Hey!
is there a way to validate the model? I read somewhere “recall” and precision are two parameters to evaluate the performance.
How do we implement this in the above given example?
Or is there a way to calculate RMSE for this model?
Hi, how come you used 1-cosine similarity to calculate your similarity matrix for the Item Based Collaborative Filtering example?
Pingback: Recommender for Slack with Pandas & Flask – Liip AG Liip
Hello
i got this problem <> and nothing shows up. Then I change order by sort_values but still with the same, nothing shows up.
Thank at lot, i like so much the post
This is the warning: FutureWarning: order is deprecated, use sort_values(…)
Please change the line to:
#data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].order(ascending=False)[:10].index # in sample
data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].sort_values(ascending=False)[:10].index
THANK YOU SO MUCH!
Thank you.
Thanks for this great tutorial. All codes worked fine and they are easy to follow. However, my question is: is this really the collaborative filtering algorithm? I watched Andrew Ng’s videos on collaborative filtering and it involves the minimization of a cost function which contains both the features and the parameters. I don’t see this minimization step in this tutorial at all. Please kindly clarify my confusion.
https://www.youtube.com/watch?v=saXRzxgFN0o
https://www.youtube.com/watch?v=i6u5ykEHSP8
https://www.youtube.com/watch?v=KkMAgWlYCAQ
Hi Salem!
Great Article. Thank you. Have you considered using GraphLab?
Hi Salem!
I tried to replicate your code on a different data set that is of the type user vs product buy-nobuy matrix. rows are users and columns are a long list of products and then cell values are 1 – for buy and 0 – for no buy. I’m getting the following error:
C:\Users\abc\AppData\Local\Continuum\Anaconda3\python.exe “C:/Users/abc/Documents/CF/Collaborative Filtering In Python/src/CollaborativeFiltering.py”
C:/Users/abc/Documents/CF/Collaborative Filtering In Python/src/CollaborativeFiltering.py:32: FutureWarning: order is deprecated, use sort_values(…)
trainingSet_neighbours.ix[i,:10] = trainingSet_ibs.ix[0:,i].order(ascending=False)[:10].index
C:/Users/abc/Documents/CF/Collaborative Filtering In Python/src/CollaborativeFiltering.py:56: FutureWarning: order is deprecated, use sort_values(…)
product_top_sims = trainingSet_ibs.ix[product].order(ascending=False)[1:10]
C:/Users/abc/Documents/CF/Collaborative Filtering In Python/src/CollaborativeFiltering.py:67: FutureWarning: order is deprecated, use sort_values(…)
trainingSet_recommend.ix[i,1:] = trainingSet_sims.ix[i,:].order(ascending=False).ix[1:7,].index.transpose()
Traceback (most recent call last):
File “C:\Users\abc\AppData\Local\Continuum\Anaconda3\lib\site-packages\pandas\core\series.py”, line 1628, in _try_kind_sort
return arr.argsort(kind=kind)
TypeError: unorderable types: numpy.ndarray() < str()
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/Users/abc/Documents/CF/Collaborative Filtering In Python/src/CollaborativeFiltering.py", line 67, in
trainingSet_recommend.ix[i,1:] = trainingSet_sims.ix[i,:].order(ascending=False).ix[1:7,].index.transpose()
File “C:\Users\abc\AppData\Local\Continuum\Anaconda3\lib\site-packages\pandas\core\series.py”, line 1760, in order
inplace=inplace)
File “C:\Users\abc\AppData\Local\Continuum\Anaconda3\lib\site-packages\pandas\core\series.py”, line 1642, in sort_values
argsorted = _try_kind_sort(arr[good])
File “C:\Users\abc\AppData\Local\Continuum\Anaconda3\lib\site-packages\pandas\core\series.py”, line 1632, in _try_kind_sort
return arr.argsort(kind=’quicksort’)
TypeError: unorderable types: numpy.ndarray() < str()
Process finished with exit code 1
Could you please provide some insights?
# Create a placeholder items for closes neighbours to an item
closes neighbours , i want to also get the value of each neighbours
How i resolved this??
data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].order(ascending=False)[:10].index
when i used below code then its give all nan value
data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].order(ascending=False)[:10]
# — End Item Based Recommendations — #
Hi Mohammad I got the same error as you, did you figure this out?
Great article, well explained. If you need to calculate cosine similarity on a big data set, try this: http://na-o-ys.github.io/others/2015-11-07-sparse-vector-similarities.html
Hi how to check the performance of the model can you help in getting the performance of the model by confusion matrix or by calculating error values of MAE or RMSE on train and test data
thanks
Thank you for this blog post ! Yet, Is it normal it takes a lot of time to do the #Loop through all rows, skip the user column, and fill with similarity scores.
what if i want to recommend songs to a user who is a new user, who has not listened to any songs. But lets say i have the information of his network/friends?
Hi,
Thanks for this great article. I would like to make a suggestion to improve your implementation of item based collaborative filtering. As for loops are quite slow, you could use a vectorized implementation which is really much faster:
# — Vectorized implementation of cosine similarities — #
# Import numpy
import numpy as np
# Normalize dataframe
norm_data = data_germany / np.sqrt(np.square(data_germany).sum(axis=0))
# Compute cosine similarities
data_ibs = norm_data.transpose().dot(norm_data)
Hey!
is there a way to validate the model? I read somewhere “recall†and precision are two parameters to evaluate the performance.
How do we implement this in the above given example?
Or is there a way to calculate RMSE for this model?
Pingback: Collaborative filtering in python – datascientistharish
Pingback: Collaborative filtering for Movie data using number of views & rating in python – program faq
Pingback: 65 Free Resources to start a career as a Data Scientist for Beginners!! – Data science revolution
hi salem,
i tried to do code on different dataset that is type user vs product buy-no buy matrix. rows are users and columns are a long list of products and then cell values are 1 – for buy and 0 – for no buy. i did build a model . i just want how to evaluate this model based my result. Is there is any method for evaluating.
for i in range(0,len(data_ibs.columns)):
data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].sort_values(ascending=False)[:10].index
I got the error for this lines:
ValueError: could not broadcast input array from shape (6) into shape (10)
how to solve this?
Hi Salem,
Really helpful. I will add some validations (ex: MSE) of the model to be perfect.
def get_mse(pred, actual):
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten()
return mean_squared_error(pred, actual)
Thank u for such an interactive writing…
But how can i recommend to a new listener i mean one who haven’t listened to any song..
In that case history vector becomes 0 if not possible using collaborative filtering which one suits
can u plz help
Pingback: ¿Como transformar en un matriz panda dataframe una consulta SQL? - python sql postgresql - Preguntas/Respuestas